Web scraping is the process of extracting data from web pages in a structured format. It’s one of the most efficient ways to get data from online sites — especially if you need the data for feeding into an application or another website.
Web scraping — also known as data scraping — has numerous applications including comparing prices across multiple websites, gathering market research data, product monitoring, researching, etc. As a data scientist, I find it most useful for getting data that is not available using APIs. As a beginner or pro user, you may find it useful for comparing prices or collecting data from the web.
In this write-up, I will introduce you to two methods for web scraping. The first method is a beginner-friendly way to scrape data using a ready-to-use solution. The second method is a programmer-friendly way to scrape data using Scrapy, which supports powerful scraping if well done. Let’s check both of them.
Method #1: Using a scraping tool
If you are not a developer or not familiar with Python, here is the easy solution for you. There are numerous tools in the market for scraping the web, allowing you to scrape the web with zero to some programming. Surprisingly, some of the web scrapers allow you to scrape the web via their intuitive interface.
Octoparse is such a web scraping tool, which allows you to easily scrape the web. As I will detail later in this post, Octoparse lets you perform scraping in three simple steps. Fortunately, it does offer a free plan via its app to scrape data locally, allowing you to perform small scraping tasks with zero investment.
Moreover, Octoparse has many advanced features for getting hands-on web scraping without programming. I find its templates interesting as they allow you to scrape data from popular websites without configuration. For example, you can choose a prebuilt template to scrape product data from Amazon or eBay.
Using automatic data extraction
Octoparse is powerful yet handy. The reason being it supports detecting and extracting data from web pages spontaneously. Though I found it mostly works with a list or table of data, it is the fastest way to get started. Here’s how:
- Go to https://www.octoparse.com/signup and sign up for a free account.
- Once you confirm your email address and log in to Octoparse, you will see a screen saying “Account’s ready!” > click Start Free Premium Trial.
- Enter your card details or checkout with PayPal to activate the trial.
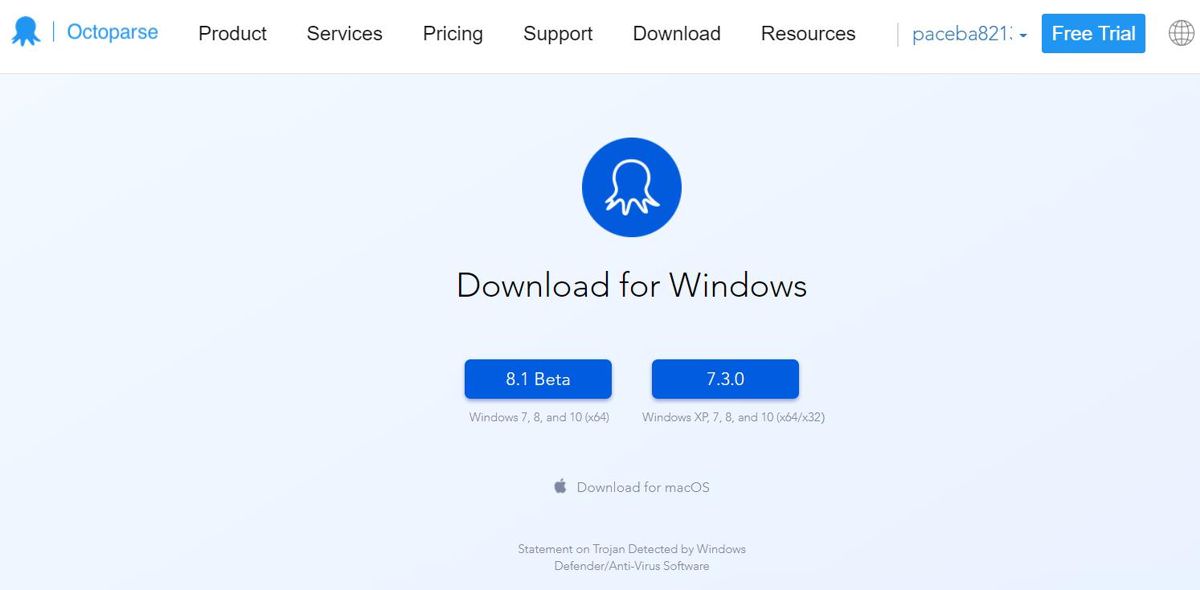
- Click Download Our Free Software to download its application for your platform — Windows or macOS. Then, click the 8.1 Beta button.
- Extract the downloaded zip archive and open Octoparse Setup 8.1.xx.exe to install its application. Then, follow the on-screen instructions.
- After it is installed, open Octoparse and log in to your account. Do remember to check Remember Password and Auto Login options.
- You will see the interface of Octoparse where you can check the video tutorials.
- Enter the web address in the text box and press Start. For instance, I am going to scrape
https://www.ebay.com/itm/Amazon-Echo-Dot-4th-Gen-With-Clock-2020-Smart-Speaker-Alexa-All-Colors-NEW/363219888368here. - Octoparse will load the web page and try to detect and extract potential data. Under Tips, uncheck Click on a “Load More” button option.
- If the data shown in the bottom half of the application is not something you are looking for, click Switch auto-detect results to see more.
- Once you see the expected data, click the Create workflow button.




Using manual data extraction
Sometimes, Octoparse’s automatic data extraction features may not be enough for you. Maybe the web page you are trying to extract data from is complex or dynamic. Whatever be the case, you are in good hands with Octoparse since it also allows manually selecting the data to extract. Here’s how to do it:
- Follow the steps under “Using automatic data extraction” till step #8.
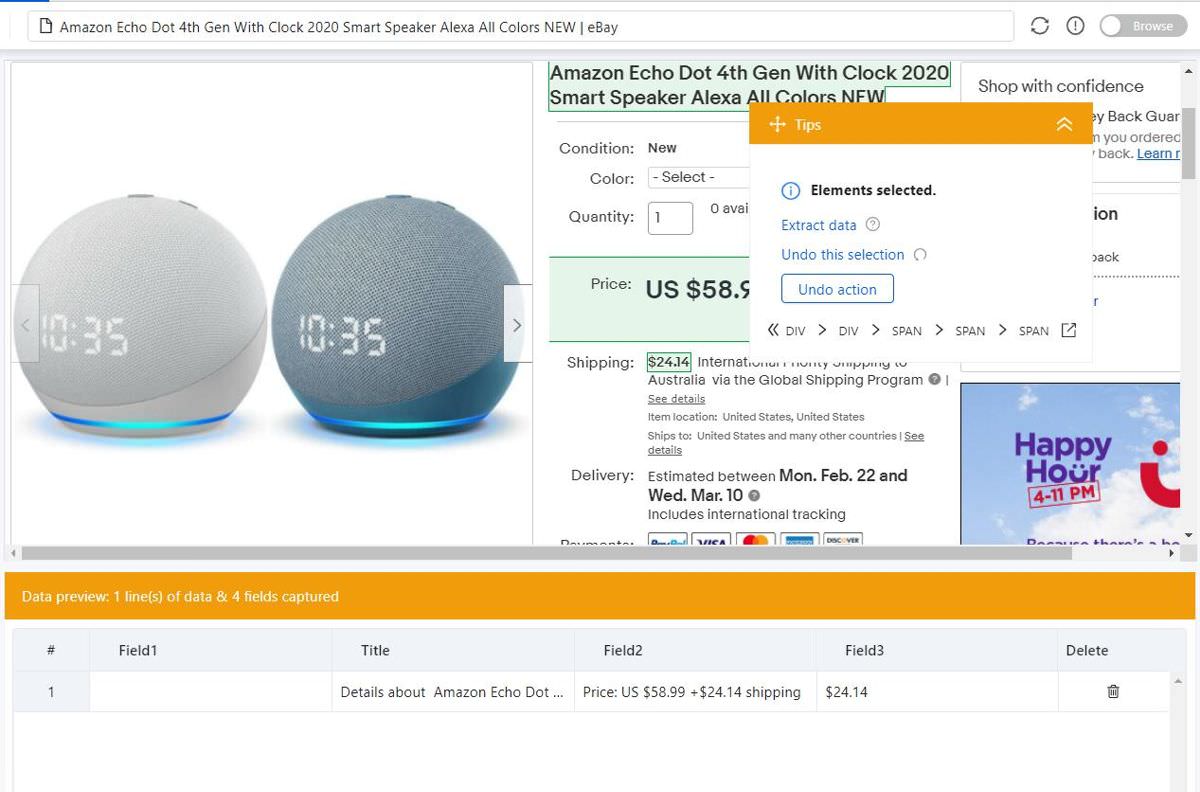
- Octoparse will start loading the web page and detecting potential data to extract. Under Tips, click Cancel Auto-Detect to extract data manually.
- Now click on data items on the web page to extract those data. For example, I clicked the title, price, and shipping of Echo Dot 4th Gen.
- In the Tips dialog, click the Extract data option to test the workflow.
- Finally, click Save near the top-left corner of Octoparse to save it.

Postrequisite
Alright, we have created the task to extract pricing information from eBay via Octoparse. However, it is not yet automated. That is, you must run it manually for now. That said, let’s check how to automate it to extract data periodically:
- In your task tab, click Run near the top-left corner of Octoparse.
- Click the Schedule task (Cloud) button in the Run Task dialog.
- Click one of Once, Weekly, Monthly, and Repeats, then configure it.
- Finally, click one of Save or Save and Run buttons to save it.
Finally, it is completed. Your task will run automatically in Octoparse Cloud per your configured schedule. You can view the data by clicking on Dashboard, clicking on the More button of your task, and selecting View data > Cloud data.

Method #2: Using a custom program
If you have checked out the first method and want more control or you are a programmer and want to learn the programmatic method to scrape web pages, you must try this method. We will utilize Scrapy to build the solution. I assume you have hands-on knowledge of working with HTML & CSS and Python.
Scrapy is an open-source framework for extracting data from websites. It is a popular data scraping tool among data scientists. In my experience, it works great for small or big projects, but you may require to properly configure it and implement third-party tools to make it effective for large scraping projects.
Prerequisite
Do you know about selectors in CSS? On any web page, selectors help to identify and select specific elements. You can read about selectors on W3Schools. For example, if you want to find all top headings on a web page, you can use h1 as the selector. Here’s how to find an element’s selector in Google Chrome:
- Right-click the element on the page > choose Inspect. For example, I am trying to find the selector of the text “Example Domain” below.
- Right-click the element under Elements, go to Copy > Copy selector.


Using Scrapy
If you are trying to scrape any web page not discussed in this post or you want to scrape more data in those pages, you need to find selectors and use them. That said, let’s get started. In the example below, I am going to scrape the price of Amazon Echo Dot 4th Gen from eBay using Scrapy. Let’s get started:
- Create a new folder for your project, say “scrape-web-regularly”.
- Open a terminal, switch to this folder (i.e.,
cd scrape-web-regularly), then run the following to install Scrapy:pip install scrapy. - Create a new file in this folder (“try-one.py”) and open it in a code editor. Copy the below code into this file, make changes if needed, then save it.
- In the terminal, run the following:
scrapy runspider try-one.pyto perform the scraping. If you are writing for some other web page/site, you may try running it sometimes for getting the right selector. - If you used the exact same code as mine or used a correct selector in your custom code, you will get output similar to the example output:
- If your code is not the same as mine or you used the wrong selector, you will not see the message containing
DEBUG: Scraped from. Else, you will see a message containing{'title'— this is the scraped data.
If you get an error, read the message carefully to find the mitigation steps. For example, if the error says “error: Microsoft Visual C++ 14.0 or greater is required. Get it with Microsoft C++ Build Tools: https://ift.tt/2Mj3miN“, you should download and install it from the given link, then try again. In such cases, you can alternatively use Anaconda to download prebuilt packages.
import scrapy
class EBaySpider(scrapy.Spider):
# name of the scraper
name = 'ebay_spider'
# link or URL to scrape from
link1 = 'https://www.ebay.com/itm/Amazon-Echo-Dot-4th-Gen-With-Clock-2020-Smart-Speaker-Alexa-All-Colors-NEW/363219888368'
# links or URLs to scrape data from
start_urls = [link1]
def parse(self, response, **kwargs):
# select the element to scrape data from
for title in response.css('#prcIum'):
# extract the text data from element
yield {'price': title.css('::text').get()}
[scrapy.core.engine] INFO: Spider opened
[scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
[scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
[scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.ebay.com/itm/Amazon-Echo-Dot-4th-Gen-With-Clock-2020-Smart-Speaker-Alexa-All-Colors-NEW/3632198
88368> (referer: None)
[scrapy.core.scraper] DEBUG: Scraped from <200 https://www.ebay.com/itm/Amazon-Echo-Dot-4th-Gen-With-Clock-2020-Smart-Speaker-Alexa-All-Colors-NEW/3632198
88368>
{'price': 'US $59.99'}
[scrapy.core.engine] INFO: Closing spider (finished)
However, if you do not see any of these messages, check if the output contains DEBUG: Crawled (200). If not, Scrapy was not able to crawl or get the web page. There can be multiple reasons, so multiple troubleshooting tips:
- First of all, check if your internet connection is working properly.
- If yes, check if you can open the coded
link1in a web browser. - If not, it is a wrong link: change the value of
link1in your code. - If no success yet, there can be multiple reasons; let’s go through them:
- If you were able to get data or response at least one time, maybe you are crawling or scraping the page too many times in a short interval, causing the website to block your request. In this case, you can increase the interval between consecutive crawls or runs.
- If not, the target website is probably using some scraping protection technology, which is blocking your request to scrape the page using Scrapy. In this case, please check the next section.
Using ScrapingBee
ScrapingBee is a web scraping service for getting around scraping protection technologies and scraping the web without getting blocked. It provides a simple API for scraping the web using headless browsers and rotating proxies, letting you bypass scraping protection technologies while scraping using Scrapy.
For example, I started testing out scraping with eBay but without success. eBay detects and blocks all requests until they come from a real user using a real web browser, and so, Scrapy does not work for eBay. Also, you may find that big or popular websites work with Scrapy for some requests, but then, they start blocking the requests too. That is where ScrapingBee comes super handy.
I liked that ScrapingBee avails a free trial that includes 1,000 free calls to its API, allowing you to test its service and/or work on a small scraping project. That said, let’s get started with using ScrapingBee API in our Scrapy project:
- Go to https://www.scrapingbee.com/ and click Sign Up to register.
- Once you confirm your email address and log in to ScrapingBee, you will see its dashboard providing your account information and more.
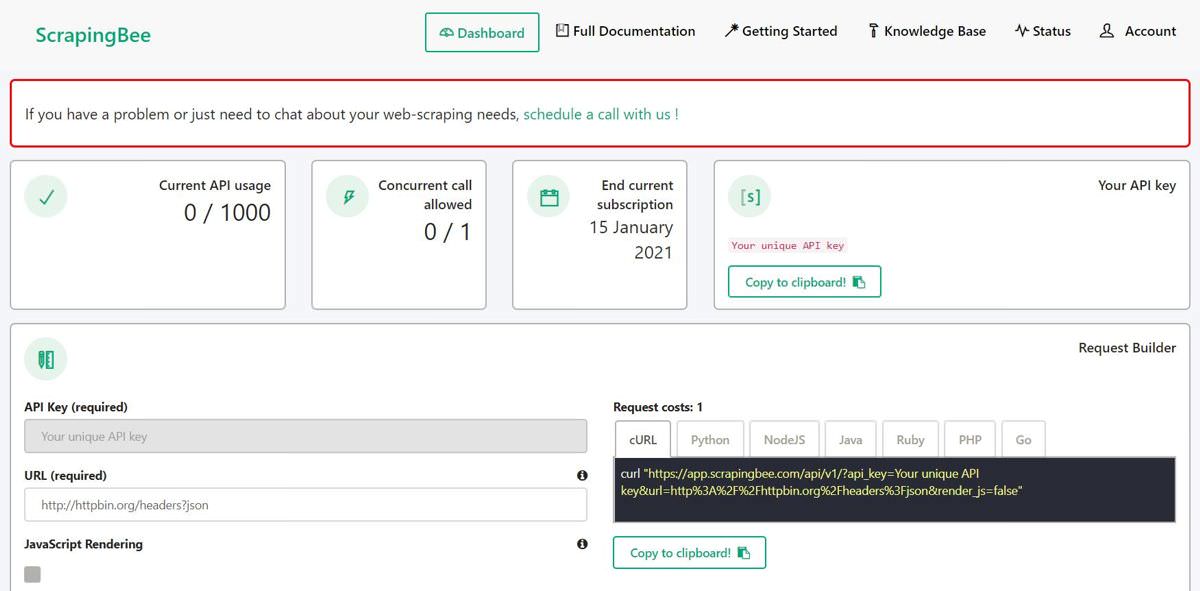
- Under Request Builder, enter the link you want to scrape under URL. If the page does not require JavaScript, uncheck JavaScript Rendering. I am trying to scrape the price of Amazon Echo Dot 4th Gen from eBay.
- Under the cURL tab, copy the link written between quotes (while skipping the “curl” word) and paste the value to the
link1in the code. So,link1 = 'https://www.ebay...becomeslink1 = 'https://app.scrap.... - Now, continue from step #4 under the section Using Scrapy above.


Postrequisite
You have completed building the scraper, i.e., the logic to scrape data. But it will not run at regular intervals yet, but instead, you need to manually run it by yourself, which is not the goal of this tutorial. Hence, let’s try to automate our custom scraper so that it runs automatically at the scheduled intervals.
In Linux OSs like Ubuntu and Linux Mint, you can use a cron job to run your scraper periodically. You can read this cron guide, and follow these steps:
- Open a terminal and run
crontab -eto edit the user’s cron file. - Enter
<CRON_SCHEDULE> cd <PROJECT_DIR> scrapy runspider try-one.pyin the cron file and save it to schedule your cron job. -
CRON_SCHEDULE: The default schedule is
* * * * *that means run it every minute. Or0 * * * *that means run it one every hour, or0 0 * * *that means run it once every day. - PROJECT_DIR: The directory wherein you created your Scrapy project. Check step #1 under the Using Scrapy section above.
Now, your scraper will run periodically at the scheduled time using cron in Linux OSs. If you are using Windows 10, you can use Task Scheduler to schedule your scraping task to run periodically. Read my guide to automate repetitive tasks.
That is all about scraping a website using a ready-to-use platform like Octoparse and a custom-built program using Scrapy and ScrapingBee.
The post How to Scrape Webpages at Regular Intervals (Automatically) appeared first on Hongkiat.
from Irvine Business Signs https://ift.tt/3c7fjBX
via Irvine Sign Company

